最近有个需求,用户在发表观点时,如果内容有 url,那么需要将该网址的标题爬取出来,再用a标签将这个 url 和标题括起来,现在将思路写下来。
具体效果如某星球发表观点类似:
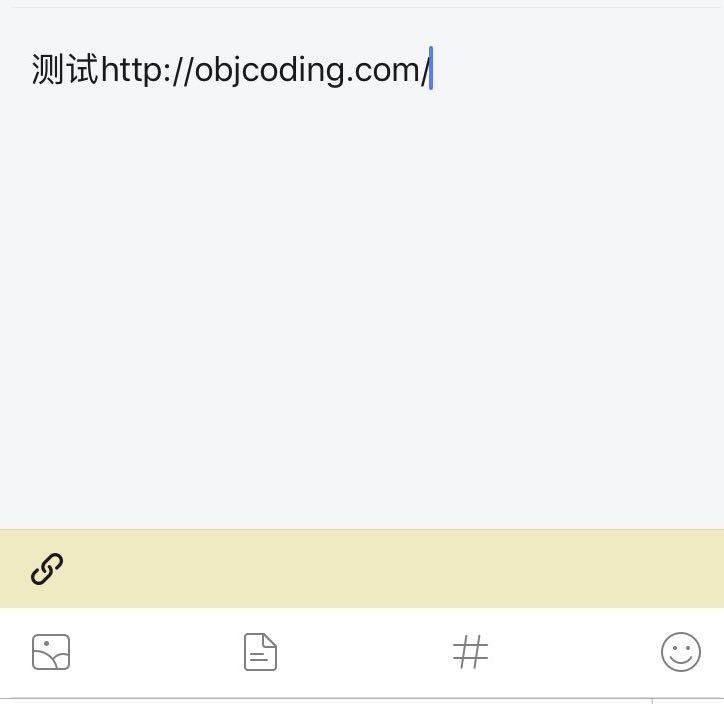
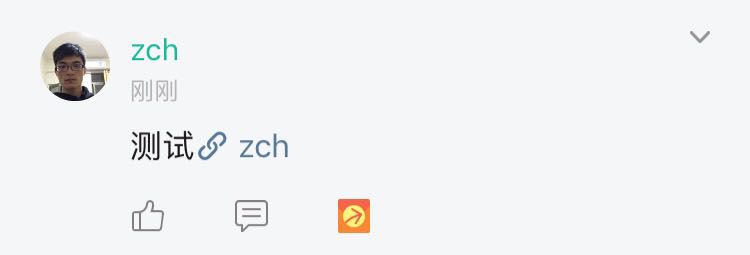
我用的是 Java.net 包中的 URL 类来获取网页内容,它可以代表一个这个 url 中的内容,并封装成一个对象来表示,调用 openStream() 方法读取url指定的网页内容,同时将该流装饰成一个字符读取流,这里有个问题,我发现网上的例子很多都是直接将 url 的内容一行读取出来再用正则表达式去分析,我认为这样会很消耗性能,所以我将思路改成一个字符一个字符地读取,同时判断如果将标题标签读取完,就将流关闭。
代码实现如下:
public static String getHtmlTile(String url) {
URL myUrl;
StringBuilder title = new StringBuilder();
BufferedReader in = null;
try {
myUrl = new URL(url);
// 打开流,并装饰成一个具有缓冲区的字符读取流
in = new BufferedReader(new InputStreamReader(myUrl.openStream(), "UTF-8"));
int temp;
StringBuilder check = new StringBuilder();
int count = 0;
// 一个字符一个字符地读取
while ((temp = in.read()) != -1) {
char c = (char) temp;
// 如果没读到标签,不会将流写入title中
if (StringUtils.isNotBlank(title.toString())) {
title.append(c);
}
check.append(c);
// 判断check缓冲区的字符是否读取到title标签
if (check.toString().contains("title>")) {
// 清空check缓冲区
check.delete(0, check.toString().length());
count++;
// title缓冲区从第一个title标签开始读取
if (count <= 1) {
title.append("<").append("title").append(">");
}
}
// 连续读取两个title标签之后,就不继续读取下去了
if (count > 1) {
break;
}
}
} catch (MalformedURLException e) {
System.out.println("你输入的URL格式有问题");
} catch (IOException e) {
e.printStackTrace();
} finally {
try {
if (null != in) {
in.close();
}
} catch (IOException ioe) {
ioe.printStackTrace();
}
}
if (StringUtils.isNotBlank(title.toString())) {
// 去除标题标签
return title.toString().replace("<title>", "").replace("</title>", "");
}
return "点击链接";
}
做完了网页爬取标题内容,我们还差一步,就是将用户观点内容的url用a标签括起来,这里会用正则表达式来做识别url的任务,代码实现如下:
public static String compileUrl(String content) {
Pattern p = Pattern.compile(
"((http|ftp|https)://)(([a-zA-Z0-9\\._-]" +
"+\\.[a-zA-Z]{2,6})|([0-9]{1,3}\\.[0-9]{1,3}" +
"\\.[0-9]{1,3}\\.[0-9]{1,3}))(:[0-9]{1,4})*(/[a-zA-Z0-9\\&%_\\./-~-]*)?");
Matcher m = p.matcher(content);
while (m.find()) {
content = content.replace(m.group(), "<a href= \"" + m.group() + "\">" + UrlUtl.getHtmlTile(m.group()) + "</a>");
}
return content;
}
测试效果:
public static void main(String[] args) {
System.out.println(compileUrl("哦哦哦http://objcoding.com啊啊啊http://wwww.baidu.com哈哈哈"));
}
// 哦哦哦<a href= "http://objcoding.com">zch</a>啊啊啊<a href= "http://wwww.baidu.com">百度一下,你就知道</a>哈哈哈
由后台最肥的超级大丁丁提供技术支持。
