上一篇跟大家描述了 Kafka 集群扩容的方案与过程,这次就跟大家详细描述 Kafka 分区重分配的实现细节。
Kafka 为用户提供了分区重分配的执行脚本 kafka-reassign-partitions.sh,脚本内容如下:

ReassignPartitionsCommand 类为我们提供了分区重分配的功能,主要有如下方法:
-
generateAssignment() 函数:对应执行脚本的 –generate 参数,为用户生成新的分配方案,输出格式为 json 字符串;
-
executeAssignment() 函数:对应执行脚本中的 –execute 参数,需要注意的一点是,这并不是真正执行分区数据迁移的动作,只不过是将新的分配方案保存在 zk 中,路径为 /admin/reassign_partitions。
以下是源码执行过程:
1、–execute 命令执行分区重分配任务,kafka会在zk的节点 /admin/reassign_partitions,并将分配策略存储到上面:
kafka.admin.ReassignPartitionsCommand#executeAssignment:
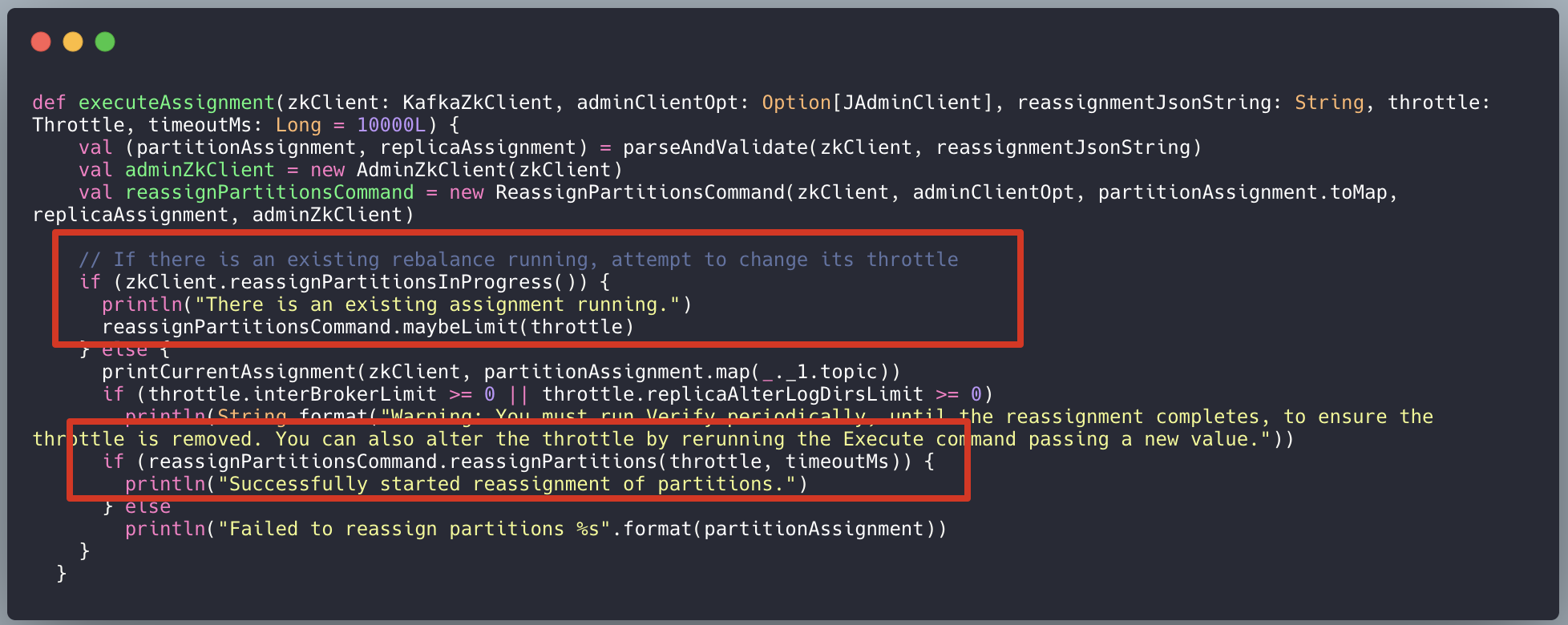
在调用脚本向 zk 提交 Partition 的分区重分配策略,将策略提交到到 zk 前需要进行一步判断,如果分区重分配还在进行,那么本次执行计划是无法提交的,意味着集群当前只能有一个分区重分配执行。
2、将分配策略更新到 zk 上
kafka.admin.ReassignPartitionsCommand#reassignPartitions:
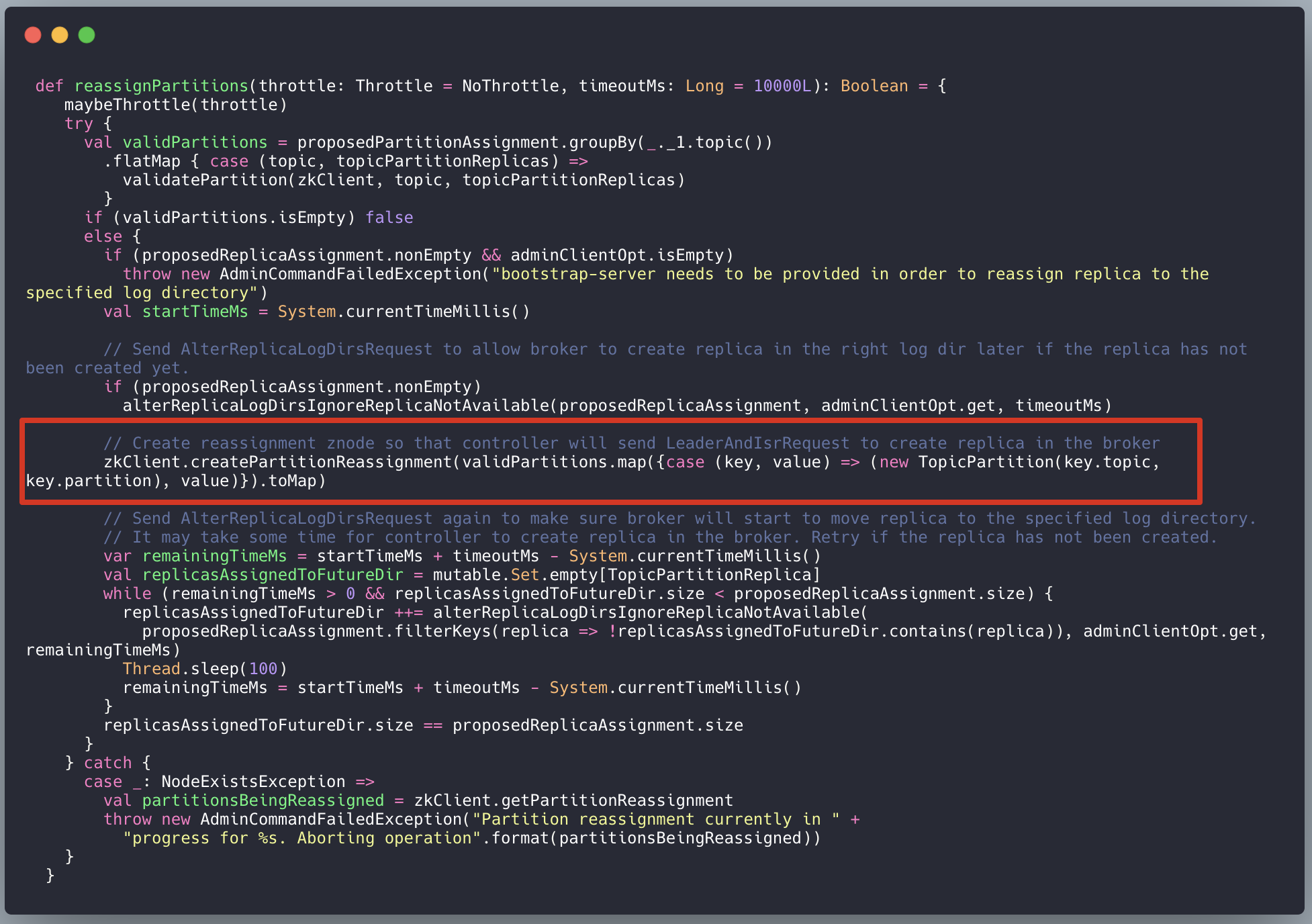
3、Kafka Controller 有一个监听器,监听 zk 节点 /admin/reassign_partitions 变化,将分配策略更新到 zk 上,该监听器就会被触发,然后执行分区重分配逻辑:
kafka.controller.KafkaController.PartitionReassignment:
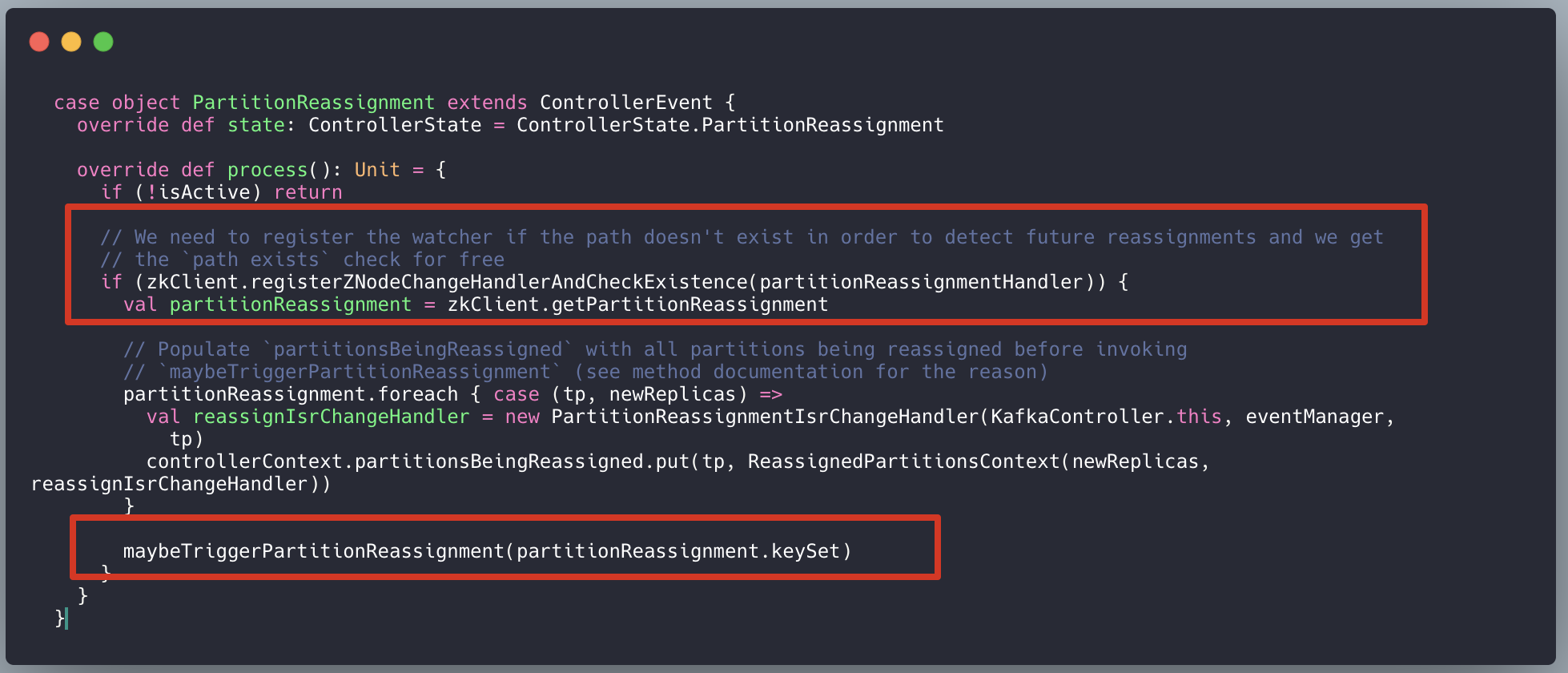
该监听器会将正在迁移的 Partition 添加到 partitionsBeingReassigned 中,记录当前正在迁移的 Partition 列表。
4、触发分区重分配前,判断如果分区没有变更,则不执行分配,实现的逻辑如下所示:
kafka.controller.KafkaController#maybeTriggerPartitionReassignment:
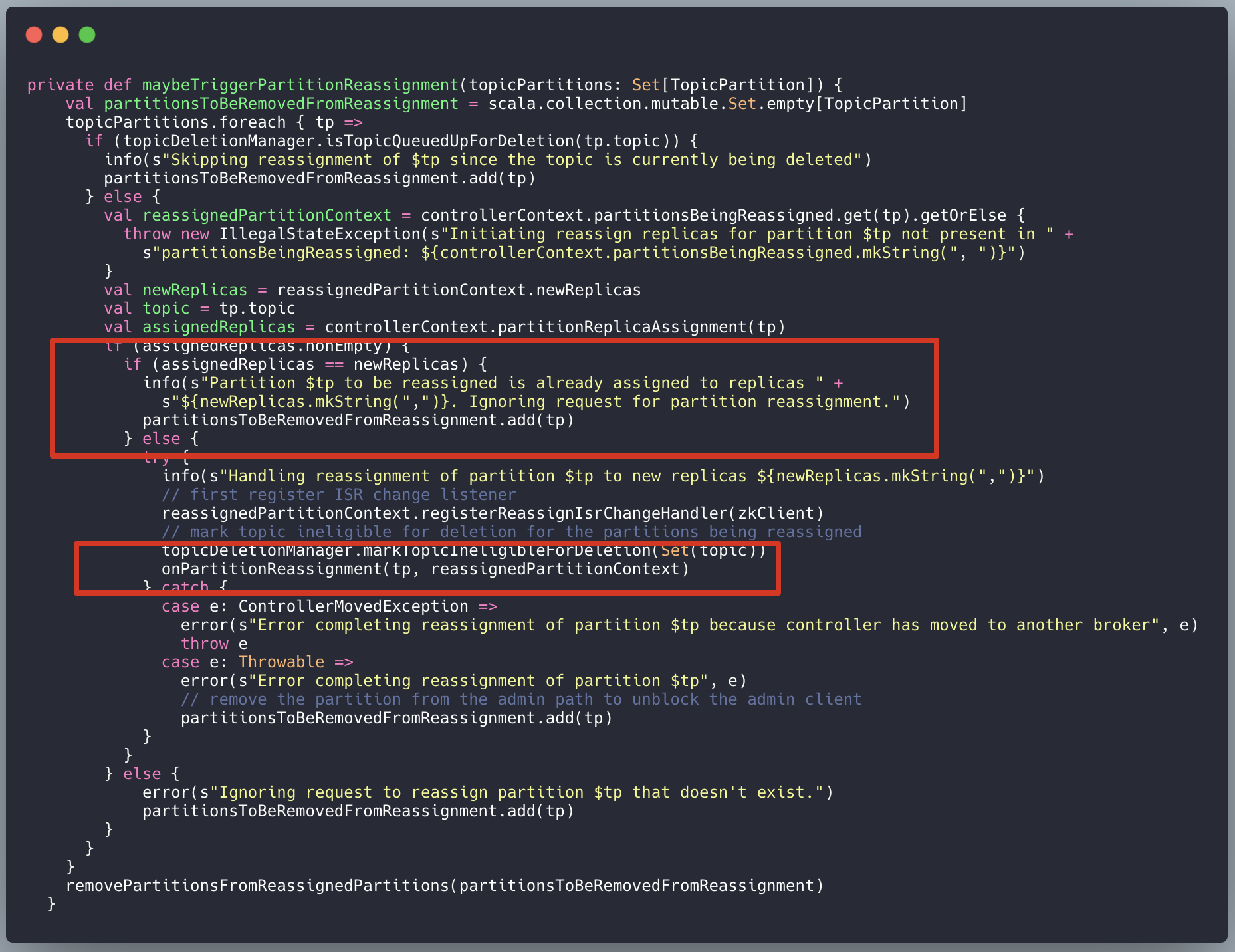
5、如果分区变更,执行真正的分区重分配策略: kafka.controller.KafkaController#onPartitionReassignment:
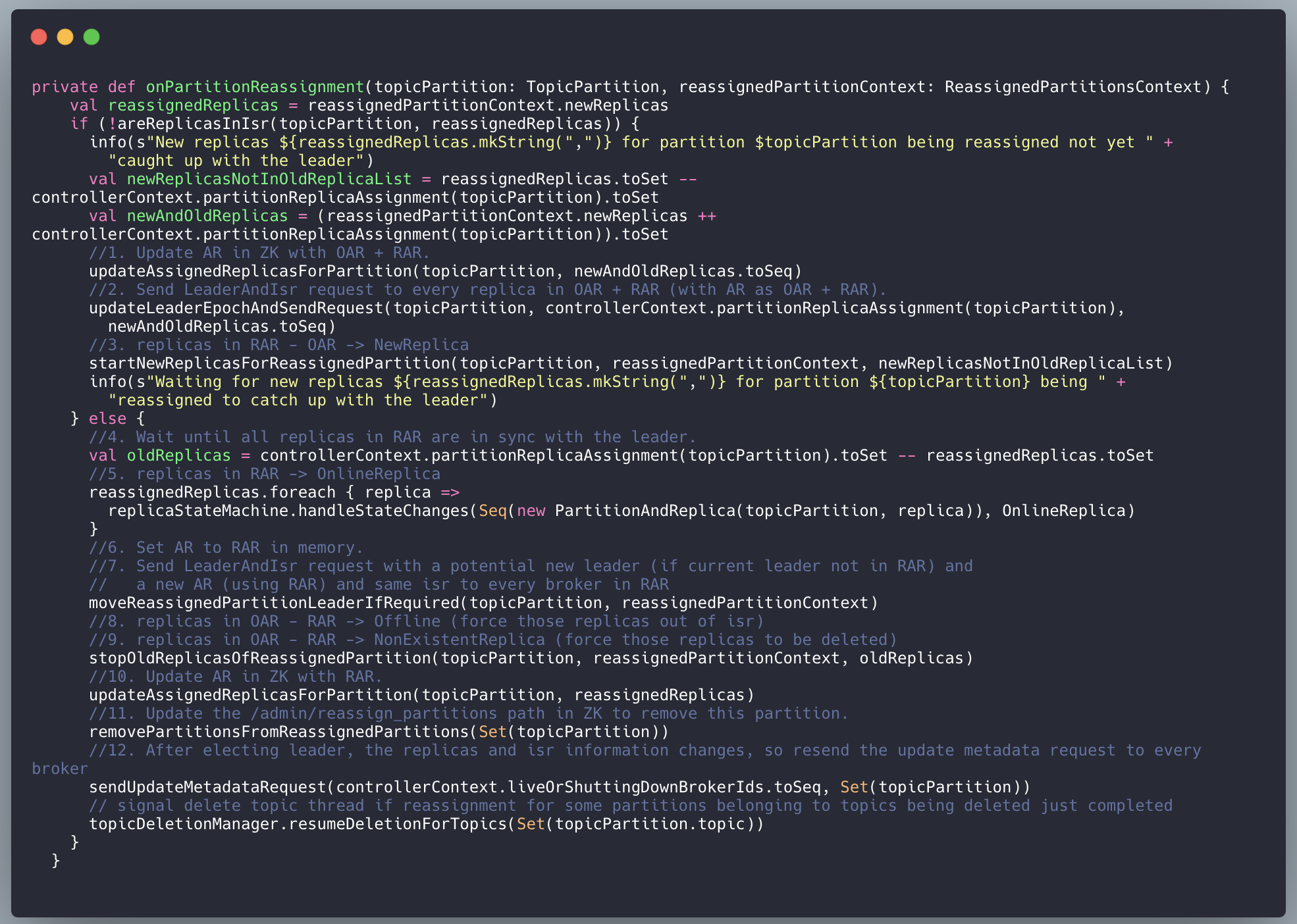
以上 onPartitionReassignment 是 Kafka 执行分区重分配真正的核心方法,从注释可看出有几个专有名词,特此说明一下:
- RAR:Reassigned replicas,即
--generation参数生成的新分配副本列表; - OAR:Original list of replicas for partition,原来的分区副本列表;
- AR:current assigned replicas,当前副本列表 ,随着分配过程不断变化,最终会等于 RAR + OAR;
- RAR-OAR:RAR 与 OAR 的差集,即需要创建、数据迁移的新副本;
- OAR-RAR:OAR 与 RAR 的差集,即不需要创建、数据迁移的副本。
从源码注释可看出,整个分区重分配共有 12 个步骤,我将这个过程主要归类分为以下几个大步骤:
- 将新的分配(RAR + OAR)保存到 zk,并触发 controller 进行分区重分配;
- 创建 RAR 的副本,并与 leader 同步,同步完后设置成在线状态,此时该分区的 ISR 列表集合变成了 RAR + OAR;
- 在 RAR + OAR 中进行 Leader 选举;
- 将 OAR-RAR 得到的差集踢出 ISR,并进行删除;
- 删除 zk 对应节点,并通知 broker 更新 Metadata。
举个例子:
现在有个分区,它原来的副本列表 OAR = {1, 0, 2},新分配的后的副本列表 RAR = {2, 3, 5},那么在分区重分配过程中,该分区的 AR、Leader 以及 ISR 变化如下:
- AR {1,0,2} -> Leader/ISR 1/{1,0,2} :初始状态;
- AR {1,0,2,3,5} -> Leader/ISR 1/{1,0,2} :创建 RAR - OAR 差集的新副本
- AR {1,0,2,3,5} -> Leader/ISR 1/{1,0,2,3,5} :新的副本追上了 Leader 的位移,并加入 ISR
- AR {1,0,2,3,5} -> Leader/ISR 2/{1,0,2,3,5} :Preferred Leader 选举
- AR {1,0,2,3,5} -> Leader/ISR 2/{2,3,5} :将 OAR - RAR 差集的副本踢出 ISR
- AR {2,3,5} -> Leader/ISR 2/{2,3,5} :删除 OAR - RAR 差集的副本
这里需要说明一下需要 Leader 选举的两种情况:
- 如果 RAR 中的 Preferred Leader 副本与 OAR 中的 Preferred Leader 副本不一样,则需要重新选举;
- 以上条件满足,但 Preferred Leader 所在的 Broker 崩溃了。
把以上分析的几大步骤,再结合「记一次 Kafka 集群线上扩容」这篇文章中 kafka-manage 的截图数据,就更加好理解了。
