ISR(in-sync replica) 就是 Kafka 为某个分区维护的一组同步集合,即每个分区都有自己的一个 ISR 集合,处于 ISR 集合中的副本,意味着 follower 副本与 leader 副本保持同步状态,只有处于 ISR 集合中的副本才有资格被选举为 leader。一条 Kafka 消息,只有被 ISR 中的副本都接收到,才被视为“已同步”状态。这跟 zk 的同步机制不一样,zk 只需要超过半数节点写入,就可被视为已写入成功。
follwer 副本与 leader 副本之间的数据同步流程如下:
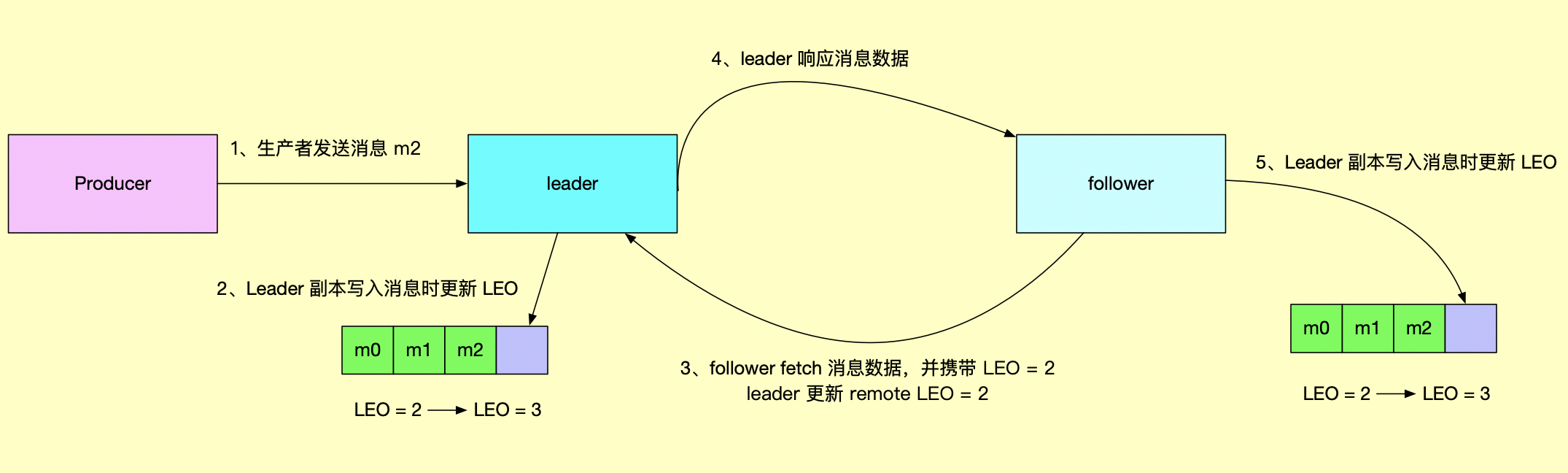
从上图可看出,leader 的 remote LEO 的值相对于 follower LEO 值,滞后一个 follower RPC 请求,remote LEO 决定 leader HW 值的大小,详情请看「图解:Kafka 水印备份机制」。
这也就意味着,leader 副本永远领先 follower 副本,且各个 follower 副本之间的消息最新位移也不尽相同,Kafka 必须要定义一个落后 leader 副本位移的范围,使得处于这个范围之内的 follower 副本被认为与 leader 副本是处于同步状态的,即处于 ISR 集合中。
(1)0.9.0.0 版本之前的设计
0.9.0.0 版本之前判断副本之间是否同步,主要是靠参数 replica.lag.max.messages 决定的,即允许 follower 副本落后 leader 副本的消息数量,超过这个数量后,follower 会被踢出 ISR。
replica.lag.max.messages 也很难在生产上给出一个合理值,如果给的小,会导致 follower 频繁被踢出 ISR,如果给的大,broker 发生宕机导致 leader 变更时,肯能会发生日志截断,导致消息严重丢失的问题。
可能你会问,给个适中的值不就行了吗?关键在这里,怎样才是适中?如何界定?
假设现在某个 Kafka 集群追求高吞吐量,那生产者的 batch.size 就会设置得很大,每次发送包含的消息量很多,使消息发送的吞吐量大大提高,如果此时 min.insync.replicas=1,从上图可看出,生产者发送消息保存到 leader 副本后就会响应成功,表示许诺用户保存到至少一个副本的要求已经达到,消息已经成功发送。那问题来了,由于 follower 副本同步 leader 副本的消息是不断地发送 fetch 请求,此时如果 leader 一下子接收到很多消息,就会导致 leader 副本与 follower 副本的消息数量相差很大,如果此时这个差数大于 replica.lag.max.messages 的值,follower 副本就会被踢出 ISR,因此,该集群需要把 replica.lag.max.messages 的值设置成很大才能够避免 follower 副本频繁被踢出 ISR。
所以说,replica.lag.max.messages 的设计是有缺陷的,当生产者发送消息量很大时,该值也需要相应调大,但就会造成消息严重丢失的风险。
有没有更好的解决方案?
(2)0.9.0.0 版本之后的设计
在 0.9.0.0 版本之后,Kafka 给出了一个更好的解决方案,去除了 replica.lag.max.messages,,用 replica.lag.time.max.ms 参数来代替,该参数的意思指的是允许 follower 副本不同步消息的最大时间值,即只要在 replica.lag.time.max.ms 时间内 follower 有同步消息,即认为该 follower 处于 ISR 中,这就很好地避免了在某个瞬间生产者一下子发送大量消息到 leader 副本导致该分区 ISR 频繁收缩与扩张的问题了。
