最近,遇到某个集群的生产端发送延迟特别高,而且吞吐量上不去,检查集群负载却很低,且集群机器配置非常好,网络带宽也很大,于是使用 Kafka 压测脚本进行了压测。
昨天凌晨,在生产环境进行实战调优,经过不断参数改动,现将生产者相关参数设置为以下配置:
linger.ms=50
batch.size=524288
compression.type=lz4
acks=1(用户要求消息至少要发送到分区 leader)
max.request.size=5242880
buffer.memory=268435456
在生产环境的一台服务器上,使用以上参数对集群进行生产发送性能压测:
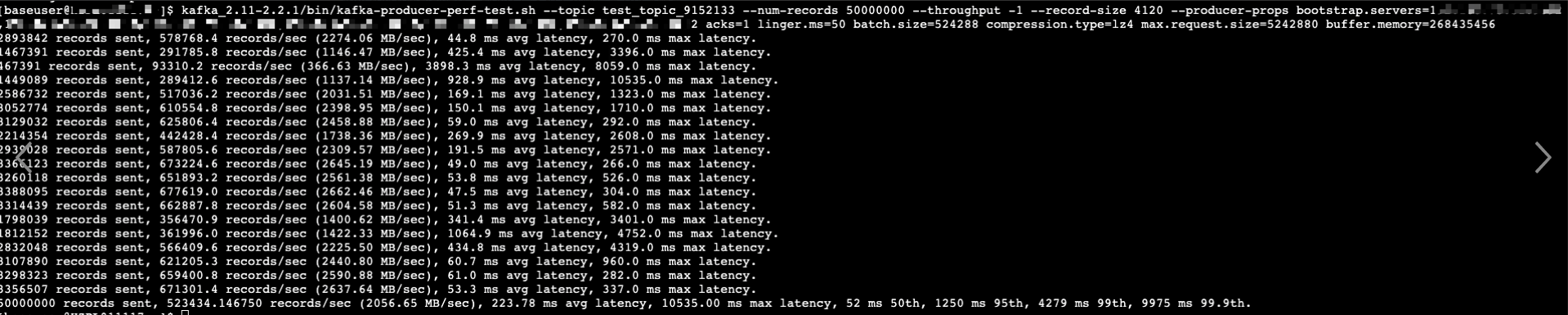
从上图可以看到,使用平均 4k 大小的消息体对集群进行压测,单个 Producer 平均吞吐量达到 2000MB/s,50w/s+!
作为对比,我还是使用同一台服务器,将调优参数去掉,再压一遍:
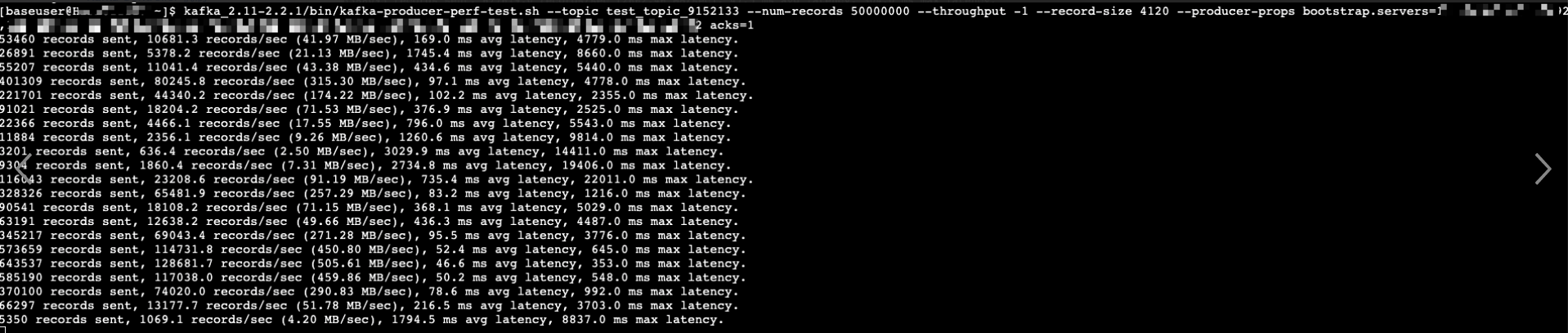
可以看到,最高的吞吐量也不过 500M/s,最低已经来到 2M/s 了。
虽然说实际客户端环境比压测环境复杂很多,但是使用压测工具已经能够证明,该集群的负载目前现在还远远没有达到瓶颈,且生产端还有待优化。
以上参数调优思想是:
1、buffer.memory=268435456
由于发送端发送频率非常快,加上由于 Spark 客户端频繁断开连接导致生产端 Sender 线程发送延迟增高,这就会造成客户端发送速率 > Sender线程的发送速率。
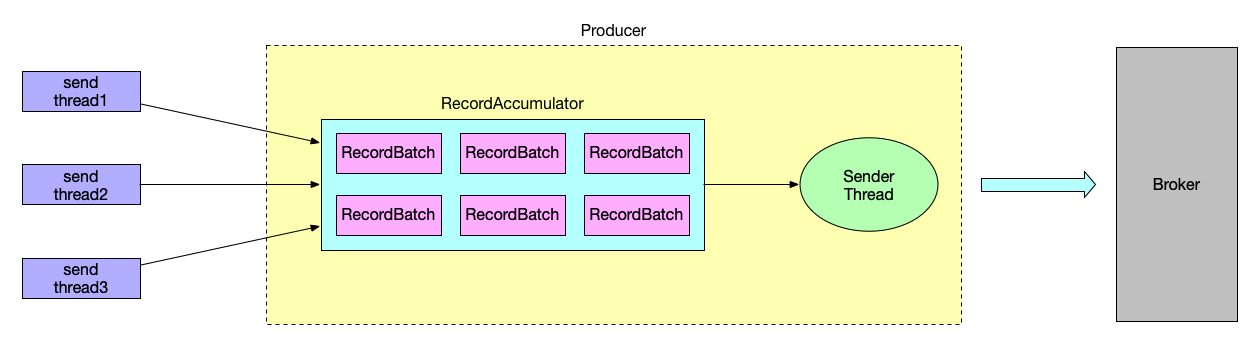
它们之间会有一个缓冲池,如果客户端发送速率 > Sender 线程的发送速率,缓冲池会很快塞满,阻塞当前发送进程,导致发送延迟增高。
注:如果 Java 进程的堆内存大小允许,可以适当再调大一些。
2、batch.size=524288
我们的客户端消息大小普遍 4k 左右,而 batch.size 默认大小为 16k,如果直接使用默认的大小,每个批次很容易被塞满,达不到缓冲的作用。而且,如果消息大小 > batch.size,则缓冲池不会对该消息产生作用,导致内存频繁被 JVM GC 回收,具体详情请看这篇文章:「深度剖析 Kafka Producer 的缓冲池机制【图解 + 源码分析】」。
3、max.request.size=5242880
该参数主要作用是限定每次发送到 broker 的数据大小,默认值为 1M,如果太小,会导致生产端与 broker 的网络交互增多,加上加上由于 Spark 客户端频繁断开连接导致生产端 Sender 线程发送延迟增高。
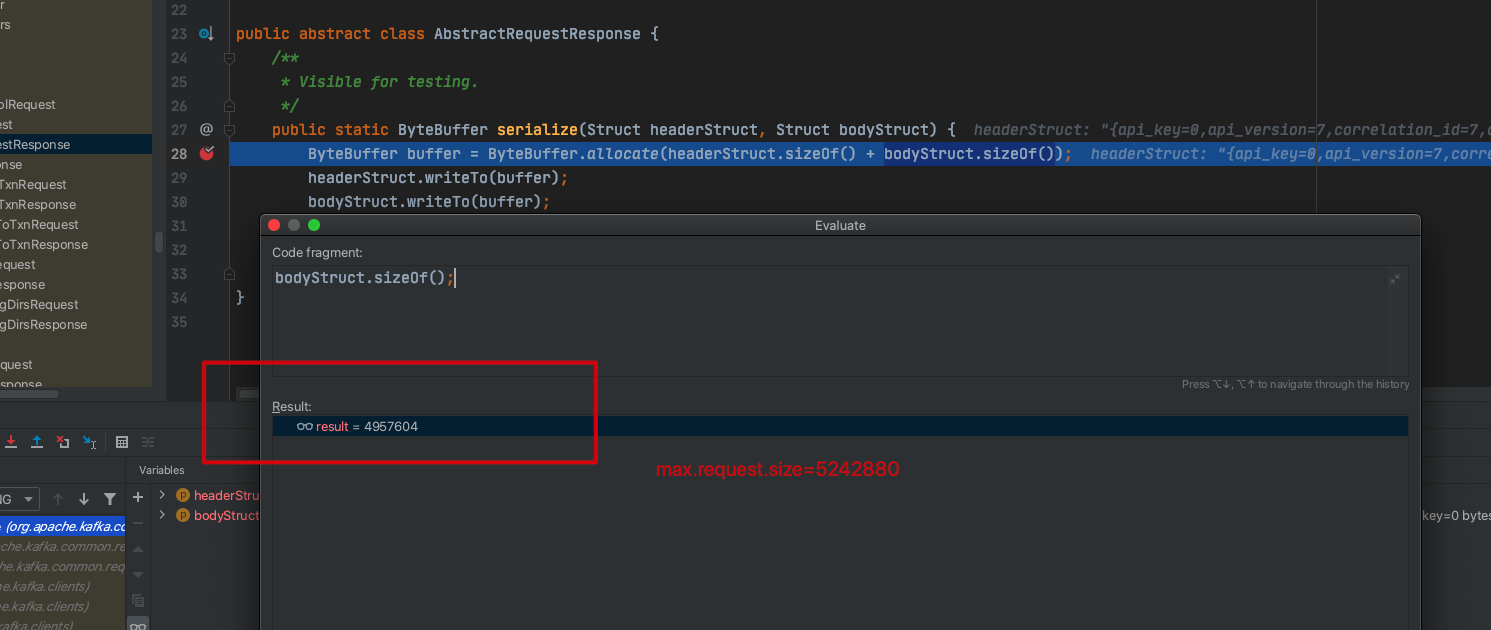
如上图,当 max.request.size=5242880 时,请求 broker 发送的数据量不大于 max.request.size。
如果频繁地进行网络交互,延迟也会随之增高,该值可以根据集群网络带宽适当设置更大一些,我们的集群带宽非常充足,可以适当再调大些。
4、linger.ms=50
为了防止某些时候发送速率很低,batch 没有装满导致不发送消息的情况,需要适当调整该值,与 batch.size 的大小适当调整为最佳大小。
注:以上参数仅仅是根据我的生产集群实际情况给出的值,具体参数还是需要结合你的集群本身的情况,机器的配置,网络的带宽不同,都会影响参数的值。
