某天晚上打球打得正嗨,突然间收到运维电话,说某个 Kafka 集群 RT 值非常高,使用该集群的用户也发现了消息堆积现象,此刻我意识到问题的严重性,于是急忙跑回办公室查看这个问题。
分析问题现象
打开消息控制台(以下简称 ZMS),查看该集群的状态,发现 RT 值比平时高了很多:
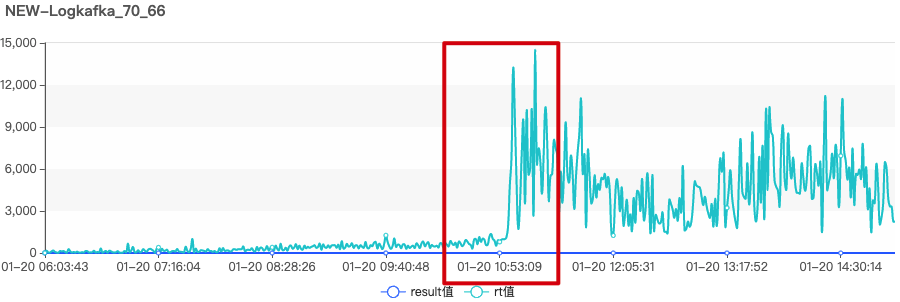
这很不正常,于是赶忙去查看各个节点日志:
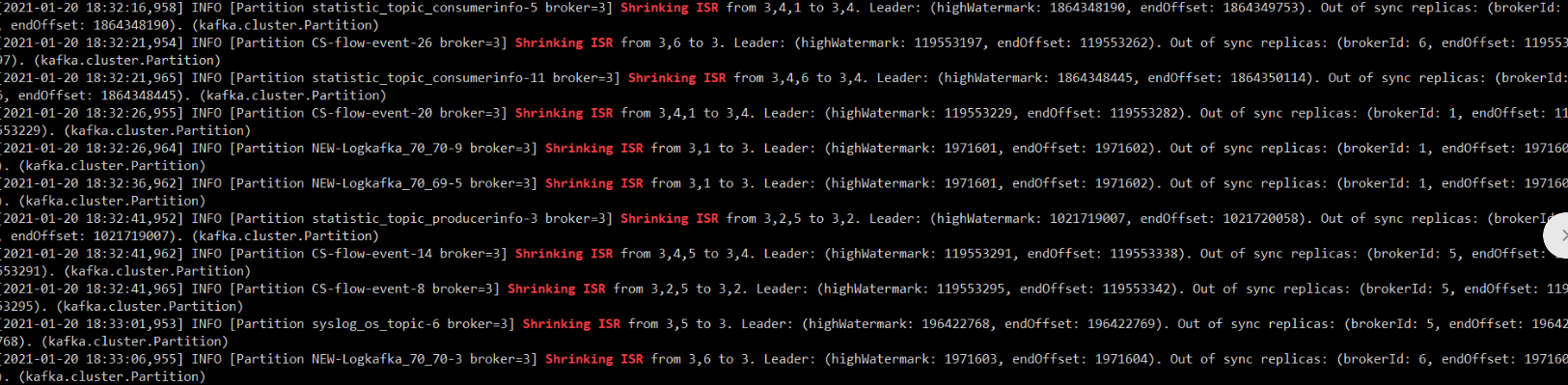
发现某个节点日志出现 ISR 频繁收缩又扩张的现象,接着查看其他节点,发现只有某个节点会出现这种现象,在 ZMS 中再次查看各个节点的 major GC 情况:
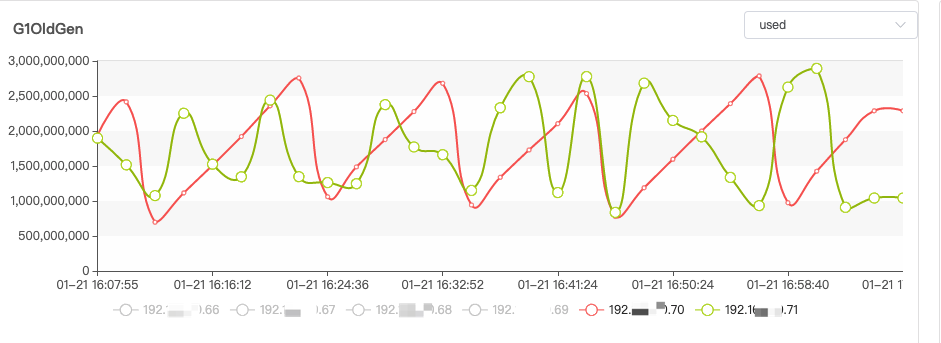
发现该节点 major GC 有点频繁而且不规律,接着还发现了一些连接断开的日志:
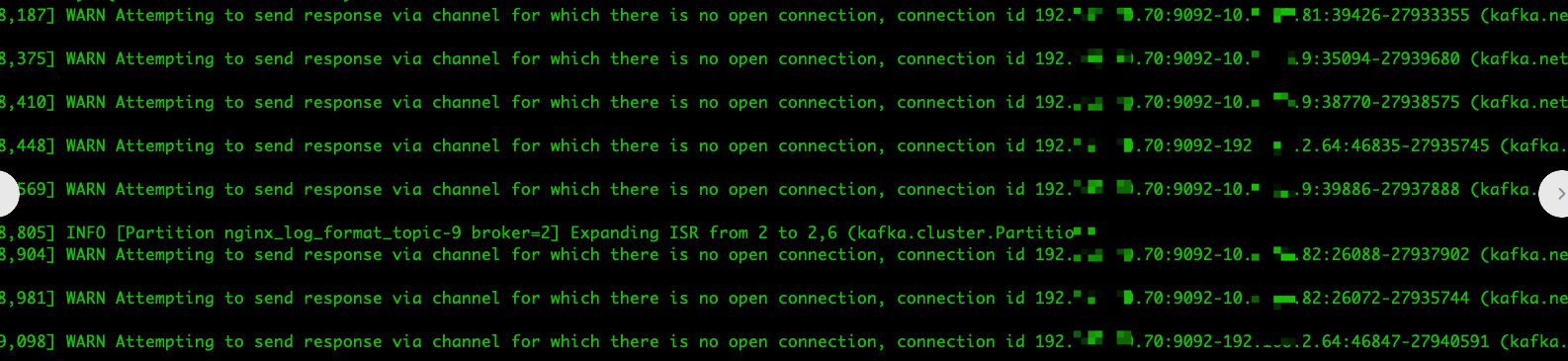
同时还发现该节点流出的流量不正常:
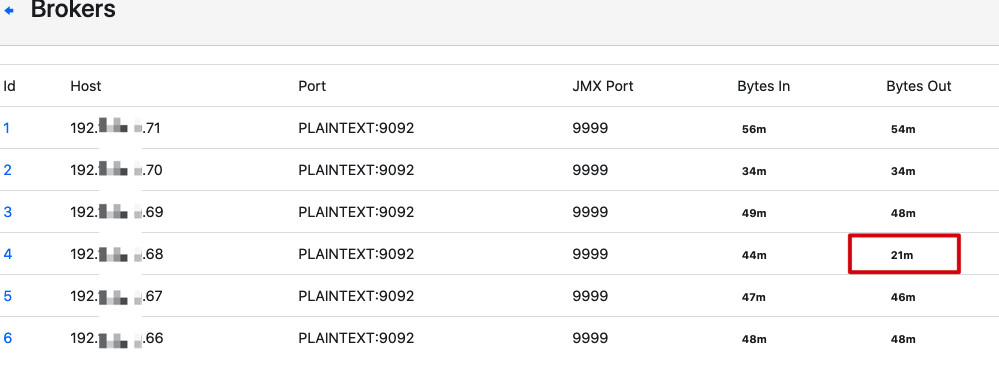
从上图可看出,该节点的流出流量少了很多,猜测是因为 follower 副本拉取消息的流量少了很多,也是该节点的 Leader 副本会将 follower 副本踢出 ISR 列表的表现现象。
根据业务方反馈,在 1 月 12 日那天,这一天增加了很多客户端连接集群。
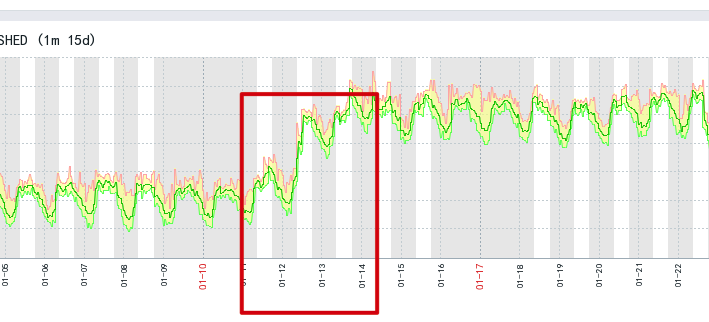
导致每个节点在这一天开始大概增加了 4 千个 TCP连接,这个问题也是从这一天开始出现的,从上图也可以看出,连接数也是从这天开始飙升的。
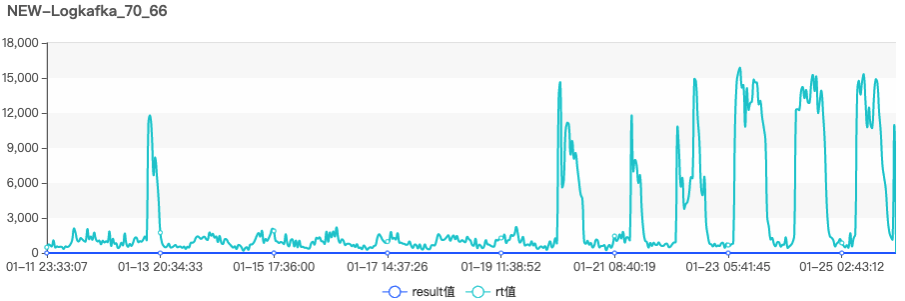
从上图也可以看出,而且该集群的 RT 值升高也是从这一天开始发生的。
以上根据 Broker 日志、GC、连接数量、RT 值等多个方面查处问题的具体现象。
排查解决问题
既然是增加了那么多客户端连接,那是不是由于 Kafka Broker 处理请求不过来,导致请求阻塞,超时后被断开了,因此才会出现 ISR 变化的同时还会出现连接断开的日志?
排查问题之前,大致讲下 Kafka 的网络线程模型,它的处理流程如下:
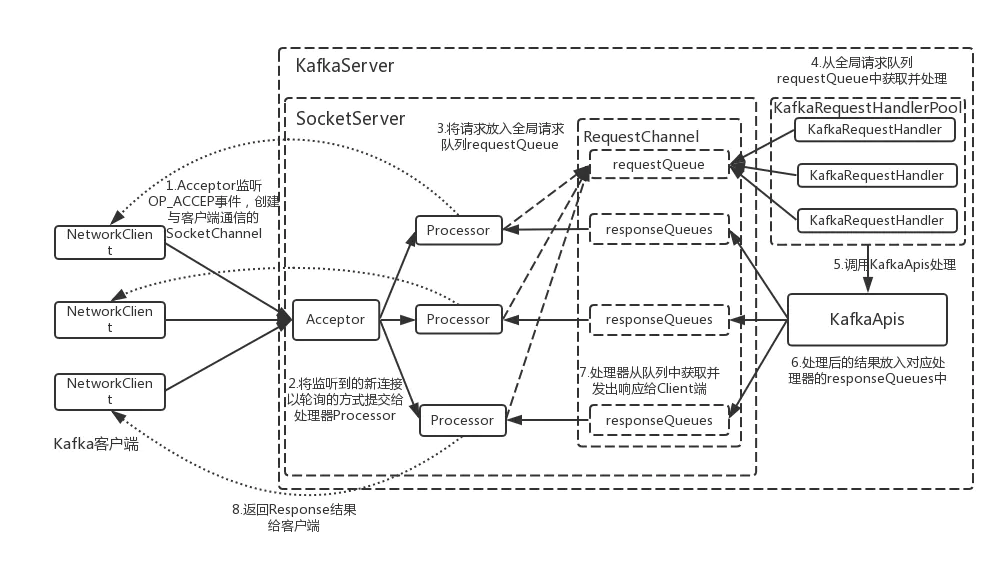
如上,要理解 Kafka 的网络线程模型可以看下 Kafka 的 kafka.network.SocketServer 类注释(不得不说 Kafka 源码在注释方面做得非常棒,值得学习):
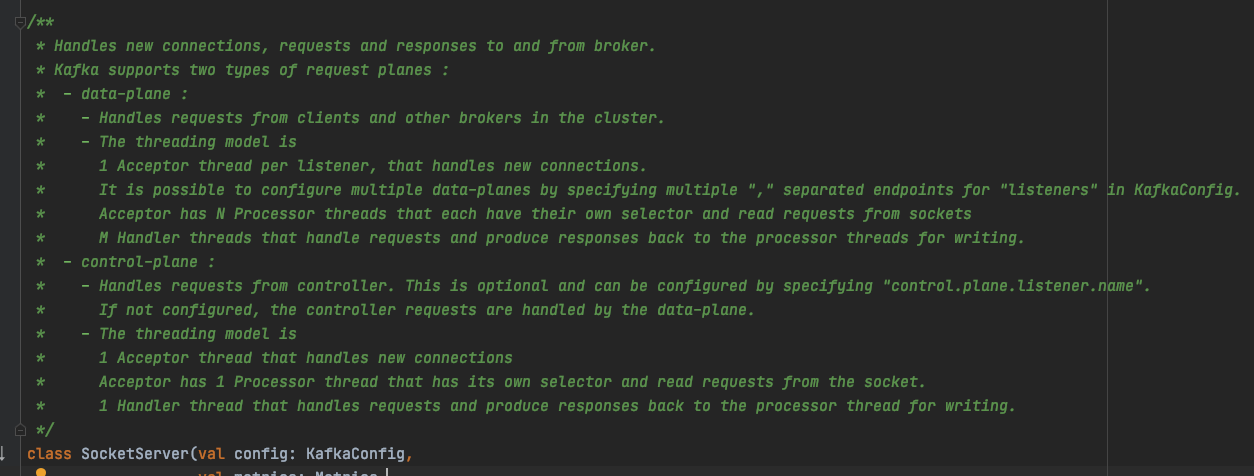
从源码注释可以看出, Kafka 的网络线程模型采用了 1 Acceptor 线程 + N Processor 线程 + M Handler 线程的线程模型。
其中 Processor 线程可以通过 num.network.threads 参数设定,默认为 3,专门用于处理接受请求和发送响应;Handler 线程可以通过 num.io.threads 参数设定,默认为 8,专门用于处理各种请求,是 Kafka 真正用于请求处理的线程。
Kafka 为了监控为了实时监控这些网络线程的运行状态,专门提供了相关监控统计,其中:
- 提供了
kafka.network:type=SocketServer,name=NetworkProcessorAvgIdlePercent指标用于统计 Processor 线程的空闲率; - 提供了
kafka.server:type=KafkaRequestHandlerPool,name=RequestHandlerAvgIdlePercent指标用于统计 Handler 线程的空闲率。
查看各个节点 Processor 线程的空闲率情况:
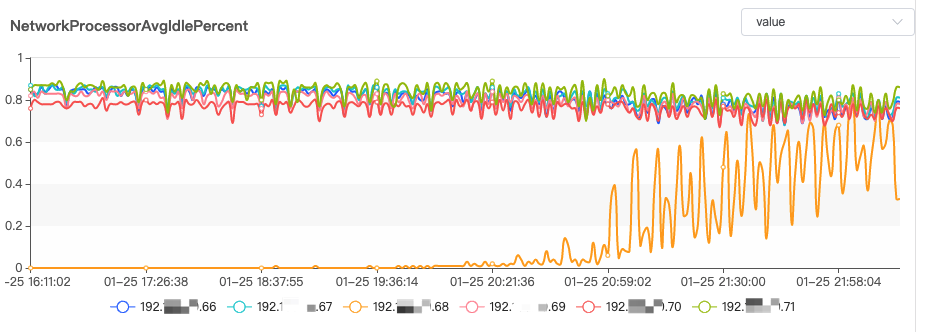
从上图可以看出,出现问题的那个节点, Processor 线程的空闲率几乎为 0,等待流量下来之后才慢慢恢复。
于是去查看节点的相关配置,发现每个节点 num.network.threads = 6, num.io.threads = 16,查看节点的 CPU 核数为 48,而且此时的 CPU 负载并不高,由此可见是因为节点设置的线程数不够,导致节点处理请求忙不过来。
于是我在原来的基础上将这两个参数同时调大一倍,分别为 num.network.threads = 12, num.io.threads = 32,并且将请求队列长度调大一倍(原来使用默认值 500) queued.max.requests = 1000,接着等待夜深人静时各个节点恢复正常后,改好参数后逐个重启。
第二天醒来后,发现即使在集群 TPS 非常高的时候,Processor 线程的空闲率依然可以维持在 0.9 左右:
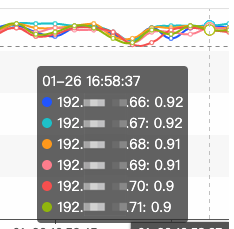
节点的 CPU 使用率也提高了:
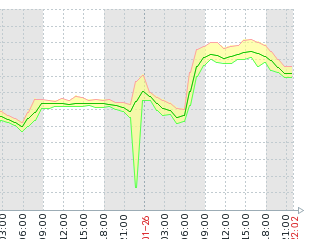
直至目前写完文章,集群现在依然是稳如老狗,集群各个节点没有再发生过 ISR 频繁变化,连接频繁断开的现象了。
总结
该问题主要是从集群 ISR 频繁变化、频繁断开与客户端连接两个问题作为出发点,根据这两个问题分析出这是导致集群 RT 值升高的直接原因,接着与业务方沟通并分析具体原因,得出业务方在某个时间点增加了大量客户端连接,也许是因为网络连接问题导致集群 ISR 频繁变化、频繁断开与客户端连接的,带着这个疑问接着去查看各个节点的网络线程空闲率情况,发现问题根源,最后根据机器配置详情适当调大各个节点网络线程模型的线程数量,顺利解决了这个问题。
在这个排查问题过程中,其实遇到不少曲折过程没有描述出来,比如为什么这个问题每次只会发生在某个节点上?本来是想获取各个节点的堆内存转储快照,但由于一些原因一直 dump 不下来,少了这块的分析。
为什么这个问题每次只会发生在某个节点上,根据对当时节点上的 TCP 连接客户端分析,以及业务方的描述,当前出现问题的节点存在某些客户端的连接非常耗资源,比如每次发送的消息量特别大,节点处理时间需要一些时间,而且 IO 线程负载已经达到极限了,导致后面的请求被阻塞,处于请求队列中的请求超时断开。
经过这次事件之后,考虑到客户端连接不可控性,ZMS 后续还需要增加集群节点网络线程空闲率全局告警功能,及时处理,以免再次发生此类现象。
下次看到日志由出现频繁断开连接,以及 ISR 频繁发生变化,就需要注意下是否是 Broker 的网络线程出现阻塞了。
以上截图很多来自中通消息服务平台 ZMS,目前 ZMS 已开源,欢迎各位大佬加入到该项目中,共同打造一体化的智能消息运维平台。
仓库地址:https://github.com/ZTO-Express/zms
