以前我们讨论的消费组,都是 group 的形式,group 可以自动地帮助消费者分配分区,且在发生异常时,还能自定地进行重平衡(Rebalance)。正常来说,group 帮助用户实现自动监听分区消费,但是在用户需要指定分区进行精确消费的场景下,由于 group 的重平衡机制,会打破这种消费方式,这不前段时间某项目就有个需求是这样的:
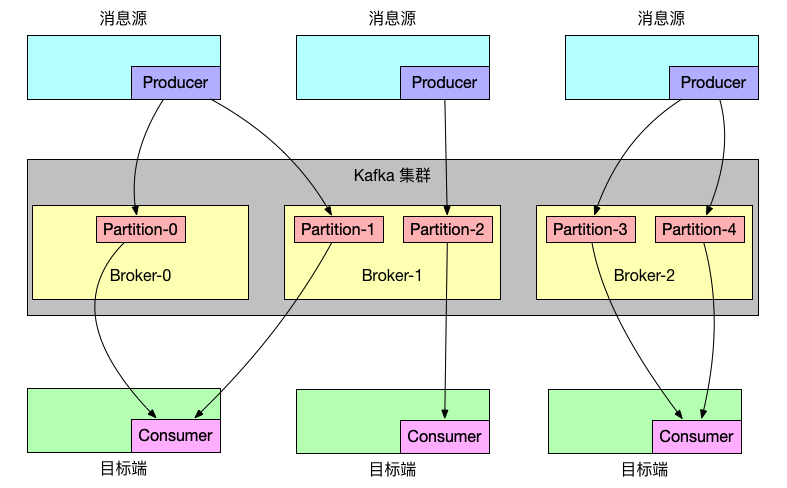
消息源端有若干个,每个消息源都会产生不同的消息,目标端也有若干个,每个目标端需要消费指定的消息源类型。
在以往,由于消费组的重平衡机制会打乱这种消费方式,只能申请多个主题对消息进行隔离,每个消息源将消息发送到指定主题,目标端监听指定的主题。这么做肯定没有指定分区消费这么优雅了,每增加一种消息源,都需要新增一个 topic,且消费粒度不能灵活组合。
针对以上问题,Kafka 的提供了独立消费者模式,可以消费者可以指定分区进行消费,如果只用一个 topic,每个消息源启动一个生产者,分别发往不同的分区,消费者指定消费相关的分区即可,用如下图所示:
但是 Kafka 独立消费者也有它的限定场景:
1、 Kafka 独立消费者模式下,Kafka 集群并不会维护消费者的消费偏移量,需要每个消费者维护监听分区的消费偏移量,因此,独立消费者模式与 group 模式切勿混合使用!
2、group 模式的重平衡机制在消费者异常时可将其监听的分区重分配给其它正常的消费者,使得这些分区不会停止被监听消费,但是独立消费者由于是手动进行监听指定分区,因此独立消费者发生异常时,并不会将其监听的分区进行重分配,这就会造成某些分区消息堆积。因此,在该模式下,独立消费者需要实现高可用,例如独立消费者使用 K8s Deployment 进行部署。
下面将演示如何使用 Kafka#assgin 方法手动订阅指定分区进行消费:
public static void main(String[] args) {
Properties kafkaProperties = new Properties();
kafkaProperties.put(ConsumerConfig.KEY_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.StringDeserializer");
kafkaProperties.put(ConsumerConfig.VALUE_DESERIALIZER_CLASS_CONFIG, "org.apache.kafka.common.serialization.ByteArrayDeserializer");
kafkaProperties.put("bootstrap.servers", "localhost:9092");
KafkaConsumer<String, byte[]> consumer = new KafkaConsumer<>(kafkaProperties);
List<TopicPartition> partitions = new ArrayList<>();
partitions.add(new TopicPartition("test_topic", 0));
partitions.add(new TopicPartition("test_topic", 1));
consumer.assign(partitions);
while (true) {
ConsumerRecords<String, byte[]> records = consumer.poll(Duration.ofMillis(3000));
for (ConsumerRecord<String, byte[]> record : records) {
System.out.printf("topic:%s, partition:%s%n", record.topic(), record.partition());
}
}
}
