-
使用 K8s 进行作业调度实战分享
最近在公司的数据同步项目(以下简称 ZDTP)中,需要使用到分布式调度数据同步执行单元,目前使用的方案是将数据同步执行单元打包成镜像,使用 K8s 进行调度。
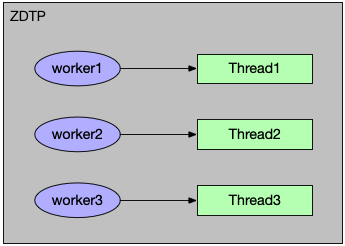
在 ZDTP 中,数据同步的动作可抽象成一个执行单元(以下称为 worker),类似于线程执行单元 Runnable ,Runnable 放入一个队列中等待线程的调度执行,执行完 Runnable 即完成了它的使命。当用户在 ZDTP 控制台中创建同步任务并启动任务时,会根据同步任务的配置,产生若干个用于该任务的 worker,假设这些 worker 都在本地执行,可以将其包装成一个 Runnable,然后创建一个线程执行,如下图表示:
但是在单机模式下,就会遇到性能瓶颈,此时就需要分布式调度,将 worker 调度到其他机器执行:
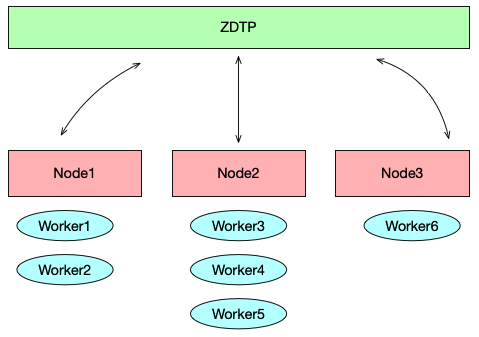
问题是我们如何将 worker 更好地调度到其它机器中执行呢?
-
我的6封情书通过中通快递送达给你
1
public void loveLetter() { String reason1 = "I love You!"; String reason2 = "I love ZTO!"; ZTO.send(MY.getGift()) .reason(reason1) .reason(reason2) .to(YOU); }用中通快递寄送一份礼物给你
不只是因为我喜欢你
而是因为我喜欢中通快递
-
图解 K8s 核心概念和术语
我第一次接触容器编排调度工具是 Docker 自家的 Docker Swarm,主要解决当时公司内部业务项目部署繁琐的问题,我记得当时项目实现容器化之后,花在项目部署运维的时间大大减少了,当时觉得这玩意还挺新鲜的,原来自动化运维可以这么玩。后面由于工作原因,很久没碰过容器方面的知识了。最近在公司的数据同步项目中,需要使用到分布式调度数据同步执行单元,目前使用的方案是将数据同步执行单元打包成镜像,使用 K8s 进行调度,正好趁这个机会了解一下 K8s,下面我就用图解的形式将我所理解的 K8s 分享给大家。
-
探讨缓存行与伪共享
最近项目中有个需求,需要用到有界队列对访问请求量进行流量削峰请求,同时作为一个缓冲层对请求处理进行后续处理,Java 内置有界队列 ArrayBlockingQueue 可以满足这方面的需求,但是性能上并不满足,于是使用了 Disruptor,它是英国外汇交易公司 LMAX 开发的一个高性能队列,了解到它内部解决伪共享问题,今天就和大家一起学习缓存行与伪共享相关的知识。
-
Seata RPC 模块的重构之路
RPC 模块是我最初研究 Seata 源码开始的地方,因此我对 Seata 的 RPC 模块有过一些深刻研究,在我研究了一番后,发现 RPC 模块中的代码需要进行优化,使得代码更加优雅,交互逻辑更加清晰易懂,本着 “让天下没有难懂的 RPC 通信代码” 的初衷,我开始了 RPC 模块的重构之路。
这里建议想要深入了解 Seata 交互细节的,不妨从 RPC 模块的源码入手,RPC 模块相当于 Seata 的中枢,Seata 所有的交互逻辑在 RPC 模块中表现得淋漓尽致。
这次 RPC 模块的重构将会使得 Seata 的中枢变得更加健壮和易于解读。
-
Kafka 消费线程模型在中通消息服务运维平台的应用
最近有些朋友问到 Kafka 消费者消费相关的问题,如下:

以上问题看出来这位朋友刚接触 Kafka,我们都知道 Kafka 相对 RocketMQ 来说,消费端是非常 “原生” 的,不像 RocketMQ 将消费线程模型都封装好,用户不用关注内部消费细节。
-
记一次关于位移提交的问题回答
今晚撸得正兴奋时,有个朋友突然问了我一个关于位移提交的问题,他最近刚接触 Kafka,在一篇博客中看到了这么一段话:

然后他给我举了不是那么常规的一个问题,如下:
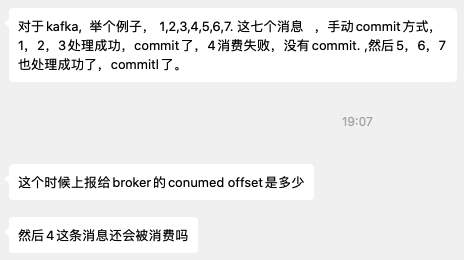
我一看问题就觉得有点奇怪了,我知道这个朋友肯定是从 RocketMQ 过来的,因为在 RocketMQ 的位移提交机制,只能是提交已消费的最小位移:
具体我有一篇文章专门详细地分析了 RocketMQ 的位移提交机制:RocketMQ 位移提交源码分析
因此,RocketMQ 是不会发生上面所说的情况。
我觉得产生这种疑惑是因为之前使用 RocketMQ 的时候,由于不用自己处理位移提交,一切交给 RocketMQ 处理了,而恰好 RocketMQ 提交位移的机制只能提交未消费最小偏移量以杜绝消息的丢失,导致了这位朋友切换到 kafka 需要手动处理位移的时候,产生了以上的困惑。
对 Kafka 来说,它提供了手动位移提交的机制,可以暴露出来让用户自行实现位移的提交,也就意味着你可以对分区的位移有控制权,这完全取决于你本身的实现逻辑。
如果是按照例子的描述操作,此时分区最新消费偏移量就是 7 消息的位移,因为 Kafka 它本身并没有重试对列机制,基于这个前提下,如果这条消息消费失败了,要么你客户端捕捉到再进行重试消费,要么就丢弃,消费后面的消息,并提交消费位移,一切都往前看,要不然你会阻塞后面的消费。此时,4 消息就丢失了。
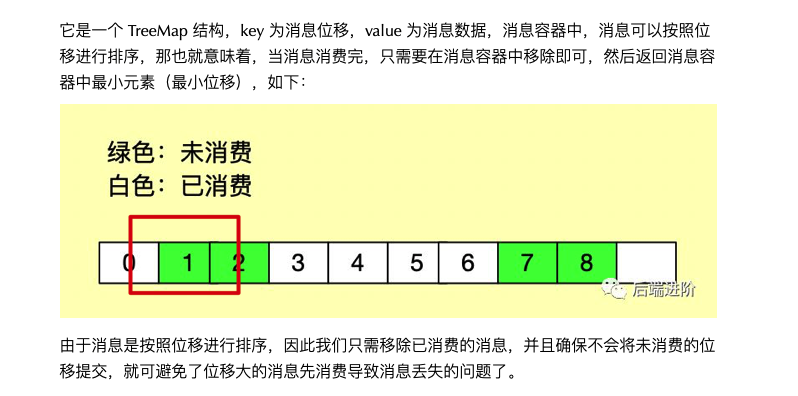
可以这么解决:自己实现一个与 RocketMQ 位移提交机制的 TreeMap 来存储消息,位移作 key,每次消费完移除,提交位移的时候只提交最小位移就好了,比如这个例子,只能提交 3 消息的位移。
-
Spring 异步实现原理与实战分享
最近因为全链路压测项目需要对用户自定义线程池 Bean 进行适配工作,我们知道全链路压测的核心思想是对流量压测进行标记,因此我们需要给压测的流量请求进行打标,并在链路中进行传递,那么问题来了,如果项目中使用了多线程处理业务,就会造成父子线程间无法传递压测打标数据,不过可以利用阿里开源的 ttl 解决这个问题。
全链路压测项目的宗旨就是不让用户感知这个项目的存在,因此我们不可能让用户去对其线程池进行改造的,我们需要主动去适配用户自定义的线程池。
在适配过程的过程中无非就是将线程池替换成 ttl 去解决,可通过代理或者替换 Bean 的方式实现,这方面不是本文的内容,本文主要是深入 Spring 异步实现的原理,让大家对 Spring 异步编程不再陌生!
-
彻底搞懂 Kafka 消息大小相关参数设置的规则
前段时间接到用户要求,调整某个主题在 Kafka 集群消息大小为 4M。
根据 Kafka 消息大小规则设定,生产端自行将 max.request.size 调整为 4M 大小,Kafka 集群为该主题设置主题级别参数 max.message.bytes 的大小为 4M。
以上是针对 Kafka 2.2.x 版本的设置,需要注意的是,在某些旧版本当中,还需要调整相关关联参数,比如 replica.fetch.max.bytes 等。
从上面例子可看出,Kafka 消息大小的设置还是挺复杂的一件事,而且还分版本,需要注意的参数巨多,而且每个都长得差不多,不但分版本,还需要注意生产端、broker、消费端的设置,而且还要区分 broker 级别还是 topic 级别的设置,而且还需要清楚知道每个配置的含义。
本文通过相关参数的解析说明,再结合实战测试,帮助你快速搞明白这些参数的含义以及规则。
-
深度剖析 Kafka/RocketMQ 顺序消息的一些坑
我不记得有多少人问过以下这个问题了:

我觉得这个问题问得很频繁,而且非常经典,在这里我就以 Kafka 为例子,说说我对 Kafka 顺序消息的一些理解吧,如有理解不对的地方麻烦留言指点一下。
- 深度剖析分布式事务,轻松掌握实现原理与应用技巧!
- 深度剖析 Seata TCC 模式【图解 + 源码分析】
- 详解 Seata AT 模式事务隔离级别与全局锁设计
- Raft: 寻找一种易于理解的一致性算法(扩展版)
- 浅谈互联网分布式架构的演进
- 一个 JDK 线程池 BUG 引发的 GC 机制思考
- Redis击穿、穿透、雪崩产生原因以及解决思路
- TCC 适用模型与适用场景分析
- Seata 分布式事务之 TCC 理论及设计实现
- 阿里经典面试题:消息队列的消费幂等性如何保证?
- 图解 Raft 共识算法:如何复制日志?
- 代码即格式:你用过这些高效工具吗?
- 面试官问我:如何设计一个秒杀场景?
- 硬核!一份来自美女读者的年中总结!
- 聊聊“频繁跳槽”这件事
- 你的 IDEA 该升级了!
- 这五天,人潮汹涌。
- Seata 分布式事务 XA 与 AT 全面解析
- 穷且益坚,不坠青云之志!
- 图解 Raft 共识算法:如何选举领导者?
- Tools 6
- SpringBoot 4
- SpringCloud 6
- Shiro 2
- AngularJS 1
- Tomcat 2
- SpringMVC 2
- Spring 8
- Java 23
- JavaScript 1
- Redis 5
- Linux 2
- Docker 14
- Go 5
- Thinking 6
- Payment 2
- Mybatis 6
- Maven 1
- RabbitMQ 3
- 推广 1
- RocketMQ 20
- Dubbo 2
- Jenkins 1
- Mysql 1
- Oracle 1
- Seata 13
- Kafka 30
- ZTO 2
- GitHub 1
- ZMS 3
- K8s 2
- DataX 1
- Kakfa 2
- Hexo 1
- PicGo 1
- Gitee 1
- Calcite 1
- Kubernetes 1
- 招聘 1
- dream 1
- Raft 3
- IDEA 1
- 职场 2
- 架构 2
- 工具 1
- 消息引擎 1
- 分布式事务 1