-
RocketMQ 位移提交源码分析
向大家提个问题: RocketMQ 消息消费进度是如何提交的,并发消费的时候,一次从 一个队列拉 32 条消息,这 32 条消息会提交到线程池中处理,如果偏移量 m5 比 m4 先执行完成,消息消费后,提交的消费进度是哪个?是提交消息m5的偏移量? 下面跟着我的节奏,撸一波源码。
-
RocketMQ 同步复制 SLAVE_NOT_AVAILABLE 异常源码分析
最近在 RocketMQ 钉钉官方群中看到有人反馈说 broker 主从部署,在发布消息的时候会报 SLAVE_NOT_AVAILABLE 异常,报这个异常的前提 master 的模式一定为 SYNC_MASTER(同步复制),从 异常码可以直接判断的一种原因就是因为 slave 挂掉了,导致 slave 不可用,但是他说 slave 一切正常。
于是我决定撸一波源码。
-
图解 Kafka 水印备份机制
高可用是很多分布式系统中必备的特征之一,Kafka 日志的高可用是通过基于 leader-follower 的多副本同步实现的,每个分区下有多个副本,其中只有一个是 leader 副本,提供发送和消费消息,其余都是 follower 副本,不断地发送 fetch 请求给 leader 副本以同步消息,如果 leader 在整个集群运行过程中不发生故障,follower 副本不会起到任何作用,问题就在于任何系统都不能保证其稳定运行,当 leader 副本所在的 broker 崩溃之后,其中一个 follower 副本就会成为该分区下新的 leader 副本,那么问题来了,在选为新的 leader 副本时,会导致消息丢失或者离散吗?Kafka 是如何解决 leader 副本变更时消息不会出错?以及 leader 与 follower 副本之间的数据同步是如何进行的?带着这几个问题,我们接着往下看,一起揭开 Kafka 水印备份的神秘面纱。
-
Kafka 分区重分配源码分析
上一篇跟大家描述了 Kafka 集群扩容的方案与过程,这次就跟大家详细描述 Kafka 分区重分配的实现细节。
-
记一次Kafka集群线上扩容
前段时间收到某个 Kafka 集群的生产客户端反馈发送消息耗时很高,于是花了一段时间去排查这个问题,最后该集群进行扩容,由于某些主题的当前数据量实在太大,在对这些主题迁移过程中话费了很长一段时间,不过这个过程还算顺利,因为在迁移过程中也做足了各方面的调研,包括分区重平衡过程中对客户端的影响,以及对整个集群的性能影响等,特此将这个过程总结一下,也为双十一打了一剂强心剂。
-
关于RocketMQ消息消费与重平衡的一些问题
其实最好的学习方式就是互相交流,最近也有跟网友讨论了一些关于 RocketMQ 消息拉取与重平衡的问题,我姑且在这里写下我的一些总结。
-
一个小小的里程碑
过去几天,这个公众号粉丝数量突破 2000 人了,这个数量可能对于一些公众号来说,连零头都不到,但对于我来说,有这么一群小伙伴看我写的技术分享,我就觉得很满足了,你们就是我坚持继续分享下去的源动力,在这里感谢这 2000 个小伙伴,感谢你们对这个公众号的厚爱。
-
Kafka重平衡机制
当集群中有新成员加入,或者某些主题增加了分区之后,消费者是怎么进行重新分配消费的?这里就涉及到重平衡(Rebalance)的概念,下面我就给大家讲解一下什么是 Kafka 重平衡机制,我尽量做到图文并茂通俗易懂。
-
Kafka消息体大小设置的一些细节
还记得前几天有个小伙伴跟我反馈发送消息时提示请求数据过大的异常吗?经过调整 max.request.size 的大小之后,又报了了如下异常:
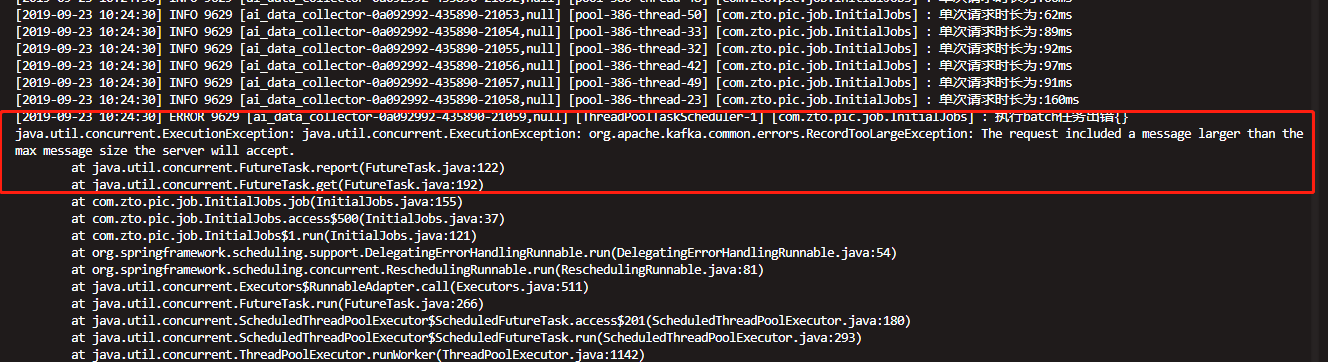
-
RocketMQ主从如何同步消息消费进度?
前面我也跟大家讲述了 RocketMQ 读写分离的规则,但是你可能会问,主从服务器之间的消费进度是如何保持同步的?下面我来给大家解答一下。
- 深度剖析分布式事务,轻松掌握实现原理与应用技巧!
- 深度剖析 Seata TCC 模式【图解 + 源码分析】
- 详解 Seata AT 模式事务隔离级别与全局锁设计
- Raft: 寻找一种易于理解的一致性算法(扩展版)
- 浅谈互联网分布式架构的演进
- 一个 JDK 线程池 BUG 引发的 GC 机制思考
- Redis击穿、穿透、雪崩产生原因以及解决思路
- TCC 适用模型与适用场景分析
- Seata 分布式事务之 TCC 理论及设计实现
- 阿里经典面试题:消息队列的消费幂等性如何保证?
- 图解 Raft 共识算法:如何复制日志?
- 代码即格式:你用过这些高效工具吗?
- 面试官问我:如何设计一个秒杀场景?
- 硬核!一份来自美女读者的年中总结!
- 聊聊“频繁跳槽”这件事
- 你的 IDEA 该升级了!
- 这五天,人潮汹涌。
- Seata 分布式事务 XA 与 AT 全面解析
- 穷且益坚,不坠青云之志!
- 图解 Raft 共识算法:如何选举领导者?
- Tools 6
- SpringBoot 4
- SpringCloud 6
- Shiro 2
- AngularJS 1
- Tomcat 2
- SpringMVC 2
- Spring 8
- Java 23
- JavaScript 1
- Redis 5
- Linux 2
- Docker 14
- Go 5
- Thinking 6
- Payment 2
- Mybatis 6
- Maven 1
- RabbitMQ 3
- 推广 1
- RocketMQ 20
- Dubbo 2
- Jenkins 1
- Mysql 1
- Oracle 1
- Seata 13
- Kafka 30
- ZTO 2
- GitHub 1
- ZMS 3
- K8s 2
- DataX 1
- Kakfa 2
- Hexo 1
- PicGo 1
- Gitee 1
- Calcite 1
- Kubernetes 1
- 招聘 1
- dream 1
- Raft 3
- IDEA 1
- 职场 2
- 架构 2
- 工具 1
- 消息引擎 1
- 分布式事务 1